In researching this thesis, I developed three implementations of Platypus, at each stage having a different level of experience with reflective programming. The three systems have the same underlying principles, but different implementation technology. Each contributed some different things to my understanding of practical and theoretical procedural reflection, whilst all agreed on the major points.
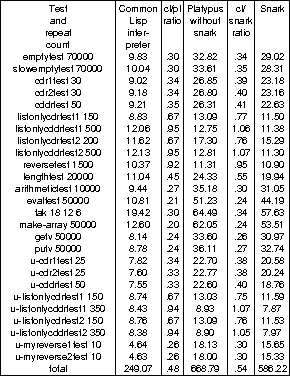
Performance testing of Platypus took the form of running a set of simple benchmarks---a mixture of the Griss tests and Gabriel tests [Gabriel 85] in Lisp and a recursive picture ``Circle Limit'' in PostScript---on a variety of configurations of the system. The same benchmarks were also run on conventional Lisp and PostScript interpreters to provide a reference point.
The tests were run for each the two versions of
the evaluator and meta-evaluator---that is, the
versions without and with the boojum and
snark functions.
For each of these versions, the tests were run
I experimented briefly with a message-passing representation of closures in Lisp. I soon realized that, for manipulating languages, this was not much better than the re-write rules, although, with each operator being an object, it was some improvement.
Although the different possible representations for languages were the same in the computational power, they were very different in their expressiveness. Both of these forms lacked expressiveness in this problem domain. Expressiveness is hard to quantify, although for many pairs of expressions of the same idea, one is often clearly more expressive than the other. Yet this is a subjective evaluation, and it is difficult even to describe the parameters we use in deciding expressiveness. Conciseness is, perhaps, an important factor: a good expression of an idea is usually more concise than a poor one. This could be quantified objectively by the number of terms used in the expression, as a poor match between an idea and the language used to express the idea usually results in extra terms that are present only to make up for the poor match. (Consider, for example, using FORTRAN instead of Lisp for consed-list manipulation, or a command shell language such as sh for Fourier Transforms.)
This was the representation I took into the first implementation (written in Cambridge Lisp), which showed it to be basically suitable. I used the same representation in C-Platypus, and extended it slightly in Platypus89, while still keeping the same structure for the actual representation of languages---the changes were concerned with tower representation and interpretation.
The slight loss in performance brought about by
adding meta-towers appears because the operation
call-meta-evaluator (used in the real,
compiled, meta-evaluator) can no longer be simply
a funcall in the substrate language, but
must now switch on whether the meta-evaluator of
the tower given as an argument to
call-meta-evaluator is shadowed by the real one.
For simplicity and efficiency, I used a different
implementation of shadowing from that used in the
normal towers; when the meta-evaluator has not
been reflected into, it simply is the
compiled one, and this is called with a Lisp
funcall. Otherwise, a Platypus closure is there,
and a level is launched to evaluate it. The
selection here is done by a Lisp typecase
form, although it would have been more consistent
with the rest of Platypus for it to be done by an
environment---another shadow map, in effect. The
reason why the real meta-evaluator can be built
into the tower at this point is that this is the
direct, and singular
grounding point of the tower. It would have been
possible, although inelegant, to connect the
meta-evaluator of an ordinary tower to that tower
by putting it in place of the rolled-up boring
section of the tower, and having the unrolling
mechanism find the thing from which to unroll
copies from elsewhere. The asymmetry of the direct
connection seems more excusable in the light of
the idea that, whereas reified data structures
continue indefinitely outward, the real
meta-evaluator must start from somewhere. This is
not so much where the buck does not stop, as where
it starts!
The development of the meta-tower system was closely linked with the theoretical development of the type system.
In all the substrate languages (Cambridge Lisp, C, and Common Lisp), the type system provided was not powerful enough in itself to support Platypus' requirements directly. Common Lisp was the best here, lacking only the facility for the programmer to add new atomic (non-structured) types, which would have been useful for local variable indices; instead, string-characters (see sections charasindex and charindex) were used for this, as being a distinct type of integer that was already available.
The first two implementations had double type systems, using both the type system of the implementation language, and a separate type system for programs running in the tower. In the first implementation, this was very confusing, as the tower type system and the meta-evaluator type system were both dynamic, and some code in the meta-evaluator used one system, and some used the other. In C-Platypus, this was not so confusing, as C's type system is static, and the static types were useful for ensuring that data stored in the tower could not be confused with non-reifiable internal data of the meta-evaluator.
In the first two implementations, the type system of the implementation language was concealed, sometimes with some effort, from programs running in the tower.
In Platypus89, the type system of the substrate language is used within the tower, which made the implementation very much quicker and easier both to construct and to understand. Common Lisp's type system is sufficiently similar to that required by Platypus that this has proved to be a good strategy.
I used the first of these in the Cambridge Lisp
implementation of Platypus, and for C-Platypus
switched to the second, to make sure that the
tower remained hidden. (C-Platypus does not reveal
higher dimensions of towers.) Having full control
of the storage heap, it was possible to make a
perfect hashing system from addresses of closures
to their shadows, thus bringing the overhead of
the mapping system down to only a little more than
that of structure access, involving, at the
machine code level, just 4 instructions: a
bitwise and, an indexed load, a
comparison, and another indexed load.
In Platypus89, I used a similar mapping system,
although using Common Lisp's gethash (which
is rather less efficient) instead of the perfect
hashing system described above.
It may be possible to make a further short-cut for speed, using numbers stored in each closure, and doing a faster form of hashing based on the number, perhaps like the address hashing used in C-Platypus. This avoids hardwiring shadows into shadowed closures, while still providing very fast access from a closure to its shadow.
(cons 1 2) (on an Orion-1, a machine of similar
processing power to an early Vax), it showed that
the ideas were viable, while leaving open-ended
the question of whether an efficient
implementation would be possible.
Platypus-0 provided a more sophisticated type
system than the substrate Lisp, using conses of
(type . value) to represent single values.
This made the coding very confusing, as it was
hard to keep track of whether a particular value
was a (type . value) pair, or a simple Lisp
value (perhaps with the type it had once had,
removed). The very simple dynamic typing provided
by Cambridge Lisp was not really powerful enough
to be helpful here.
This implementation was never sufficiently reliable to perform extensive timing tests, but it seemed to be capable of evaluating simple Lisp and FASL (a stack-based language oriented toward efficient construction of data structures, used for loading Lisp programs) code without noticeable inefficiency.
C-Platypus built some very complex data structures when starting. These were built entirely by hand-coded C routines, which were one of the major reasons for moving back to Lisp for continuing the work. The initialization code was very sensitive to changes, and difficult to maintain or re-organize. In conjunction with the use of a statically compiled implementation language, and the lack of higher dimensions of the tower, this made it impossible to extend the meta-evaluator once the tower had started to run. This is very much against the spirit of true reflective systems! The difficulty of initializing the system was one of the reasons for its being abandoned and superseded by a system built on a more powerful and flexible substrate language.
One very definite result of this stage of the work is that it is important to allow the building of the meta-evaluator incrementally, rather than providing all the pieces and putting them together at once. Retrospectively, in embarking on the C implementation of a tower, I should first have planned tools to extract the initialization code from comments or macros in the rest of the source code.
The implementation of C-Platypus included two languages, a Lisp-like one for general use (like the base language of Platypus89), and a FORTH-like language for use in program loading (in Lisp terminology, a FASL reader---a simple language for constructing data structures faster than can be done from a Lisp-like language, as its syntax and semantics are even simpler than those of Lisp).
C-Platypus made no provision for higher dimensions of the tower. Partly due to this, and partly due to the greater ease of development in Lisp, particularly concerning structuring and initializing the system, I proceeded to the third implementation, Platypus89. This left C-Platypus insufficiently reliable for timing results, so these are omitted from the result table given here.
The technological contribution of Common Lisp made a great difference here, but perhaps not as much as the further understanding of reflective interpretation that I had developed while implementing C-Platypus, and while pondering it afterwards. Two conceptual advances were most significant here:
The implementation of Platypus89 includes a
starter set of two languages: a dialect of Lisp,
and a subset of PostScript. Both of these have all
their operators defined directly in the base
language of the system, although there is nothing
to stop a language from using a mixture of
shadowed and non-shadowed operators---indeed, for
many languages this would be the case---it is
desirable, for efficiency, for a language's input
parser to use shadowed operators wherever it can;
for example, many languages will have a two-way
conditional, if... then... else..., for
which the base language's if operator may be
used; whereas FORTRAN's subroutine bodies with
GOTOS, Including Three-Way Arithmetic
GOTOs, and calculated GOTOs; or traditional
Lisp's prog... go... return... forms, are
obscure and high-level enough---away from the
natural architecture of the system---not to match
anything in the base language, and these would be
implemented by non-shadowed operators, that are
always interpreted by the meta-evaluator.
The times are in seconds, and the column ``cl/pl''
is the ratio of speeds between Common Lisp
(LispWorks) and Platypus (in the version not using
the snark function), and the column
``cl/snark'' is the ratio of speeds between Common
Lisp and the snark-based meta-evaluator.
It can be seen from this that, for these tests, Platypus89 is around one-half of the speed of a plain Lisp interpreter, or better---which is well within the one-tenth (see section 2) that I chose as my acceptance level.
I had expected the version using snark to be
slower than the other, because of the extra
procedure calls; at least one (
evaluate-anything calling snark) at each
evaluation. This did not prove to be the case; the
most likely explanation is that making each of the
most central routines smaller and simpler allows
the substrate compiler to emit more efficient
code, with a higher proportion of the live values
being in CPU registers at any one time, and less
traffic between CPU registers and the spill area
(the part of the stack frame in which local values
not currently in CPU registers are stored).
The complexity of snark and the
meta-evaluator routines build around it is, as it
turns out, closely matched to the number of
registers available on the SPARC computers used to
run it for the benchmarks.
still.ps, a program which redefines the
graphics operators of PostScript to output distilled PostScript
instead of drawing the picture itself. The PostScript system used for
comparison is Harlequin's ScriptWorks, and is run on the same kind of
computer as Platypus89 was for these tests---again, a Solbourne SPARC
system. The results of this benchmark are shown below:
This gives a performance of 42% of that of the> ScriptWorks interpreter; as with the Lisp, this is well within the 10% aimed for at the start of the> project.
The commonly used PostScript benchmarks are not particularly relevant here, as they are chosen primarily to test the graphics system attached to the PostScript language, rather than the language itself. The program used here was chosen for its complex control flow; it uses a simple picture drawn with a graphic tools, with hand-written program for repeating that picture in a tessellating pattern.
Performance testing of the reflective facilities of Platypus89 is, of necessity, largely self-referential. Here are the results of adding one level of interpretation in various versions of the system:
The times are in seconds, and the column ``pl/int ratio'' gives the ratio of speeds between Platypus shadowing the application's evaluator and operators directly, and it interpreting them. Likewise, ``snark/boojum'' ratio gives the ratio of speeds for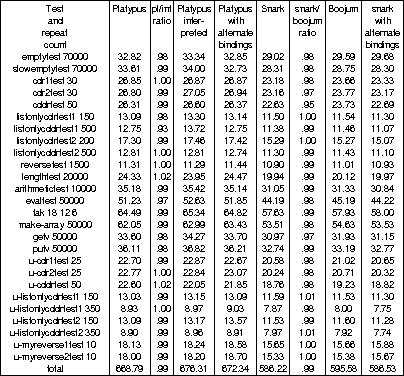
snark evaluating the
benchmarks directly, and snark evaluating
boojum evaluating the benchmarks, and so is
equivalent to the pl/int ratio of the non-
snark-based system.
Some of these figures seem anomalous, in that adding a level of interpretation improves the performance. This is not an impossibility; since a shadowed procedure and its shadow are two different extensions (implementations) of the same intension (specification) it is possible, for example, for a shadow to be less efficient than the interpreted procedure it shadows. In particular, the meta-evaluator has been optimized (by helping the substrate compiler by giving it more type information) especially heavily. However, the results are strange in places. They cannot be explained away simply as timing inconsistencies, since timing with a resolution of 10mS over a total of 10S gives an accuracy of 0.1% ---and some of the speed ratios are on the> mysterious side by twice this much.
A considerable loss in performance might be
expected from adding levels of interpretation
between the application and the meta-evaluator.
However, since the meta-evaluator consists of
several small procedures, of which not all need be
changed for many practical uses of reflection, it
need not all be interpreted, and so the overhead
is lower than it would be for reflective
architectures of coarser granularity of
reflection. As the table shows, in practice the
loss of efficiency is just a few percent.
Experiments with interpretation of the entire
evaluator showed a slowdown factor of around 40,
so the fine-grained reflective changes yield a
considerable advantage when reflection into the
interpreter is brought into play, a the cost of
extra procedure calls at all times, when compared
with an evaluator using a single procedure with a
typecase control structure to do this.
As may be expected, the boojum/
snark-based system suffers less loss of
performance on reflection, as less of the system
is given another level of interpretation by each
change. This is the positive side of the expected
trade-off, but as explained on
here, the negative side of the
expected trade-off turned out to be another
positive in the realized trade-off, and so, at
least in this situation, the snark-based
evaluator is the faster of the two.
boojum and
snark is highly parameterized, and thus
inherently difficult for a compiler to optimize as
well as it can an ad-hoc evaluator.
Changes to the levels of optimization allowed to the compiler, particularly in critical areas such as the evaluator itself, affected the performance by several percent. These changes include switching on or off various checks made by the compiled code, and adding type declarations that promise to the compiler that the expressions declared will be of specific types.
Although in general I expected code in which the same functionality was packed into fewer procedures (because of using fewer function calls), in practice smaller procedures allowed more effective use of CPU registers, and this version was slightly faster.
snark version
of the evaluator, running the Griss tests,
revealed that the following functions were on the
top of the stack 1% of the time or more:>
The profile is taken by examining the stack on a regular timed interrupt. The third column indicates how many times the function was found anywhere on the stack (counting multiple times for multiple appearances) and the fourth shows this as a percentage---thus, something always present twice on the stack will show as being on the stack 200% of the time. The next two columns show the count and percentage for the procedure being on the top of the stack. Also noticeable in the profile was the system procedure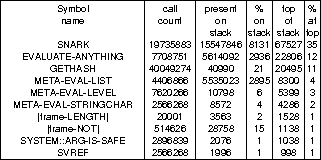
SYSTEM::DUMMY-STRUCTURE-ACCESSOR, which
implements access to defstructed data. It
was called 166919089 times, but did not occupy the
stack even 1% of the time, being called in such a>
way that it does not show in its own right (as a
machine-code subroutine, rather than as a
conventional compiled procedure). gethash
(disguised as lookup in the listings in
section 11.1) occupies 11% of the
time, which is much what I had expected.
snark takes 35% of the time (including the time>
spent in structure accessors, because of the
calling structure of the substrate system---they
do not appear on the stack in their own right).
SYSTEM::ARG-IS-SAFE is part of the
implementation of Common Lisp's apply---it
checks that the last argument (the list of further
arguments to the function) is not a circular list.
(This has since been made more efficient, which
would affect both the timings and the profiling;
but the newer version of the substrate system
inlines many functions that we are interested in
the appearance of on the profile, and so is not
used here.)
The functions named |frame-
A large piece of the system---about one third of the total---is the shadow procedures for the base language, and another one-sixth sets up the implementation of the in-tower equivalents of these---the shadowed procedures. Thus, about half of the system is the implementation of the base language, rather than of the generic language framework.
One-sixth of the code defines the data structures used in the tower, and accessor functions and macros for them. Another one-sixth defines syntactic extensions to Lisp, and defining forms for setting up procedures, operators and shadowing. About half of the remaining one sixth is the actual core of the Platypus89 evaluator, and the rest is a variety of miscellaneous support functions.
I consider this to be reasonably concise for an implementation of a language framework and reasonable subsets of two real programming languages, although it is in part parasitic on its substrate language, Common Lisp, of which, for example, the garbage collector is needed.
One thing not present in Platypus89 is a complete
type definition system, such as defstruct in
Common Lisp. This would have to be provided---but
it can, of course, be provided by an application
program and reflected in.
Platypus89 also depends on the substrate system for storage management, that is, allocation and garbage collection. C-Platypus provided these itself, which was complicated by the meta-evaluator being effectively in a separate address space from the evaluator, so the garbage collector (which was of the stop-and-copy variety) had to update the meta-evaluator's pointers into the heap as a separate action from normal block movements.
Parameterized evaluators and meta-evaluators prove to be remarkably simple, particularly when each has a recurring part that may be isolated into a procedure in its own right. These procedures---representable as 4 and 12 lines of Lisp respectively---may be seen as refined representations of what evaluation and meta-evaluation are. Having been found, they seem intuitively very natural procedural realizations of these functions.
The information provided is also in terms of Platypus' own model of execution, and may be at a lower level (in conventional terms, not reflective!) than an application programmer might expect. The raw data may need to be processed back into terms of the original language---which could be regarded as a form of decompilation, although not all of the data provided is program code. This decompilation will also reduce the bulk of data to be examined; for example, the insides of languages might not be shown when working in the context of a single language.
Decompilation of reified data should be quite general, and capable of producing sensible debugging printout into each language from any language wherever the equivalent facilities are available in both. This makes it possible, for example, for someone working in Lisp to debug a PostScript program without having to know PostScript syntax. The PostScript can be displayed as Lisp, and the interpreted definitions of the PostScript operators may be used as explanations of the PostScript language.
eq to
some other closure.
At some stages of the work, it was useful to make
the meta-evaluator print when it was doing a
level-shift, and funcall-helper print when
it was called. More general tracing than this was
too voluminous to be helpful in most cases.
Backtraces of the meta-evaluator's (Common Lisp) stack were rarely useful, as the central meta-evaluator components called each other to such a depth of indirect recursion that it was difficult to work out, and to remember, what each invocation on the stack was there for.
A breakpoint operator, which used Common Lisp's break
function, provided a read-eval-print loop in the
substrate language, which was useful for investigating the tower
contents interactively at various points in the tower's application's
execution---this was often more convenient than bulky non-interactive
printouts of the tower contents.
Occasionally it was useful to set a global variable in the substrate language to the value passed through a particular point in the meta-evaluator, so the last value that had appeared in that place could be inspected interactively at a breakpoint or after a crash.
gethash on the
substrate Lisp system, which prevented the
meta-evaluator from finding the shadow for
an operator, the meta-evaluator went into
deep recursion to interpret it from the shadowed
definition (as distinct from the shadowing
definition.) I spotted this while it was running,
broke into the execution, patched around the
gethash problem, and resumed execution from the
break. The tower now shrunk back, shedding the
unwanted levels of interpretation, and carried on
as if nothing had been wrong.
Working with mixtures of two type systems, one for the substrate language and one for the tower, was particularly confusing, and this should either be avoided, or handled with careful planning, in future work in this area.
The amount of garbage generated is a potential problem, as all stack frames are, in principle, built on the heap. The problem is reduced by using the stack frames of the substrate system to store some of the data that might have otherwise needed more frames to be built for very short-term use.
Initializing the system is complicated by the number of cross-references and self-references that must be set up. It would be useful to have some program tools for generating (or gathering) the initialization code automatically from the rest of the source code.
It is possible to produce very compact versions of both
the evaluator and the meta-evaluator, these being based
on a pair of functions, boojum and snark,
that appear to encapsulate the essence of evaluation
and meta-evaluation respectively.
And I gave my heart my heart to seek and search out by wisdom concerning all the things that are done under heaven: this sore travail hath God given to the sons of man to be exercised with.
Ecclesiastes 1:13